
大語言模型對軟體開發的影響

近期閱讀了一份文件,內容是關於大語言模型對軟體開發工作的影響,文件的連結在這:Assessing and Advancing Benchmarks for Evaluating Large Language Models in Software Engineering Tasks
這份文件聚焦於大型語言模型(LLMs)應用於軟體工程(SE)領域的效能評估。這是個有趣的題目,所謂的效能,簡單的說就是能直接在該工作任務中大幅增進效能的比例。
大家都知道現在的 AI 寫 code 已經不是什麼大不了的事,但透過 vibe coding 寫出來的 code 真的可以用嗎?符合需求嗎?品質可以嗎?能被維護嗎?
關於這些問題,我們要如何衡量 AI 的有效性呢?目前的答案是透過 Benchmark(基準)。
舉例來說,之前有的 benchmark 叫 SWE-bench,它使用了真實 GitHub issue 與 PR,測試模型是否能修正程式庫內的 bug。根據能修正多少來為模型評分。
或者是 HumanEval,是由 164 個 Python 程式任務組成,每個任務都附帶測試案例。評估方式以 Pass@k(程式通過測試案例的比例)來衡量模型的解題能力。
簡單說,基準是為了幫助我們判斷這個 LLM 在特定任務上的解題能力或成熟度。而過去大家熟知的研究大多針對程式碼生成或測試,但這份研究報告則覆蓋了需求、程式碼生成、測試、維護與品質管理等面向。
報告中回顧過去幾年發布的 291 個相關基準,算是具有一定程度的代表性。
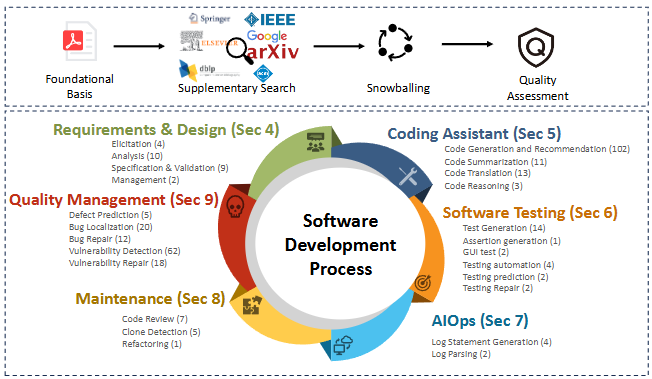
下圖,是這份研究的架構概覽:
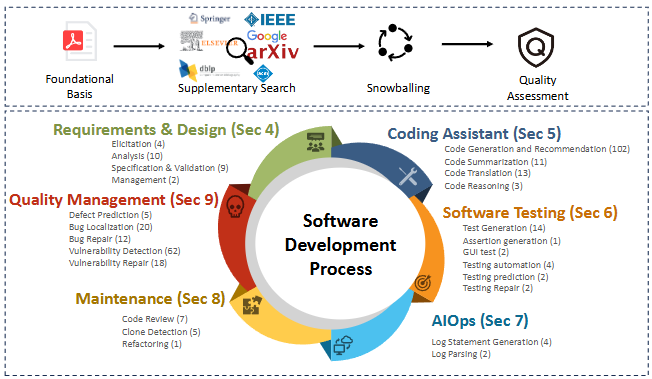
- Requirements & Design (需求與設計)需求蒐集 (4)、分析 (10)、規格與驗證 (9)、管理 (2)合計 25 個基準。
- Coding Assistant (程式輔助)代碼生成與推薦 (102)、總結 (11)、翻譯 (13)、推理 (3)合計 124 個基準(這個數字加總似乎有錯),數量最多。
- Software Testing (軟體測試)測試案例生成 (14)、斷言生成 (1)、GUI 測試 (2)、測試自動化 (4)、測試預測 (2)、測試修復 (2)合計 25 個基準。
- AIOps (智慧化維運)日誌生成 (4)、日誌解析 (2)僅 6 個基準。
- Maintenance (維護)程式碼審查 (7)、Clone 偵測 (5)、重構 (1)合計 13 個基準。
- Quality Management (品質管理)缺陷預測 (5)、錯誤定位 (20)、錯誤修復 (12)、漏洞偵測 (62)、漏洞修復 (18)合計 111 個基準,僅次於程式輔助。
基準的數量,某種程度可以說是該工作任務由 AI 完成的成熟度。所以從上方的數字看來,程式碼撰寫、測試、修 bug是目前 AI 能做得最好的項目。而需求、維護跟維運則做得相對較差。
簡單的說,脫離了程式碼,來到商業需求層面的議題,AI 能參考的數據源較少,較難給出符合需要成品。程式碼可以相對容易在網路上取得,Github、Stackoverflow 上都有許多的程式碼。
但 BRD、PRD、MRD、架構圖、佈署圖等需求文件跟架構文件,通常屬於商業機密,不太可能在網路上直接公開。這部分便是所謂的 domain know-how 跟 business know-how,我相信即便 AI 持續發展,要能完全替代人類去做這方面的任務,還是有很長的一段路要走。
而這也是未來軟體工程師跟 PM 相關職務能直接區別於 AI 的重要路線。
需求收集基準
進一步看看需求收集的基準,發現這些基準的代表性相對薄弱。例如 NFR-Review,主要收集了 iBooks (iOS) 與 WhatsApp (Android) 的使用者評論,隨機挑選 4,000 筆,最後整理出 1,278 筆需求作為基準。
而且重點著重於非功能性需求(Non-Functional Requirements, NFR),如可靠性、可用性、效能、安全性。非功能性需求通常是相對泛用的,跟 domain know-how 的綁定程度相對較低。或許具有一定程度的可參考性。
或者 Habib et al.,它是從 10 個線上需求資料集中篩選出 242 條高品質需求。所謂的高品質指的是泛用的需求,應該也會涵蓋許多非功能性需求,不過我沒找到這 242 條需求的清單,所以不太肯定它的範圍到底涵蓋到哪。
不過它有特別提到所有的需求都要符合 ISO 29148 標準,這是一套軟體工程標準,主要目的是確保需求可理解、可追溯、可驗證,並減少軟體與系統專案中的歧義與錯誤。
以下請 AI 幫忙整理 ISO 29148 標準。
這套標準主要規範「什麼是好需求」以及「如何撰寫需求文件」,核心分成三大區塊:
1. 需求的特性(Characteristics of good requirements)
一個需求應該是:
- 正確 (Correct):符合系統/用戶需求。
- 無歧義 (Unambiguous):單一解讀,不容誤會。
- 完整 (Complete):涵蓋必要條件。
- 一致 (Consistent):不與其他需求衝突。
- 可驗證 (Verifiable):能透過測試、檢查或分析來確認。
- 可行 (Feasible):能在技術、時間、成本內實現。
- 必要 (Necessary):每個需求都應支援業務目標。
- 有追溯性 (Traceable):能追溯到來源(如用戶需求或設計決策)。
2. 需求種類
- 功能性需求 (Functional Requirements, FRs)
描述系統必須做什麼,例如「系統應允許使用者登入並查詢餘額」。 - 非功能性需求 (Non-Functional Requirements, NFRs)
描述系統品質或限制,例如「系統應在 2 秒內回應查詢」、「系統必須符合 GDPR」。
3. 需求規格文件(SRS, Software Requirements Specification)
ISO 29148 提供 需求文件的範本結構,包含:
- 簡介與背景
- 系統總覽與目標
- 功能需求
- 非功能需求(效能、安全性、可靠性、可維護性等)
- 限制與假設
- 驗證與驗收準則
而為了確保每一個需求都能符合這樣的標準,Habib et al. 的作者還撰寫了另外一份研究報告 ReqBrain: Task-Specific Instruction Tuning of LLMs for AI-Assisted Requirements Generation。
在這研究中,它採用了 AI 負責撰寫符合 ISO 29148 標準的文件,並由人類進行分析與驗證的方式來進行。
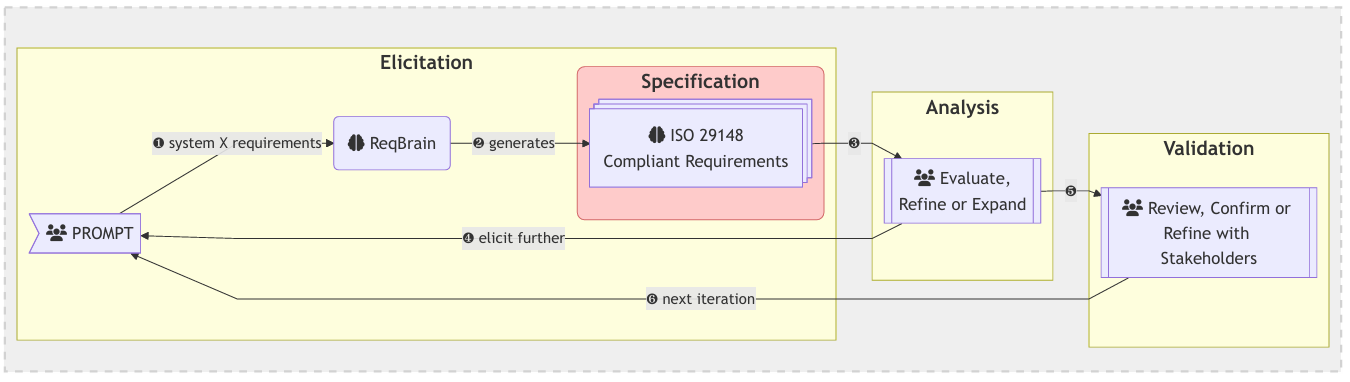
而 AI 生成的文件是否符合 ISO 29148 的標準,則由三個關鍵任務來判讀:如何
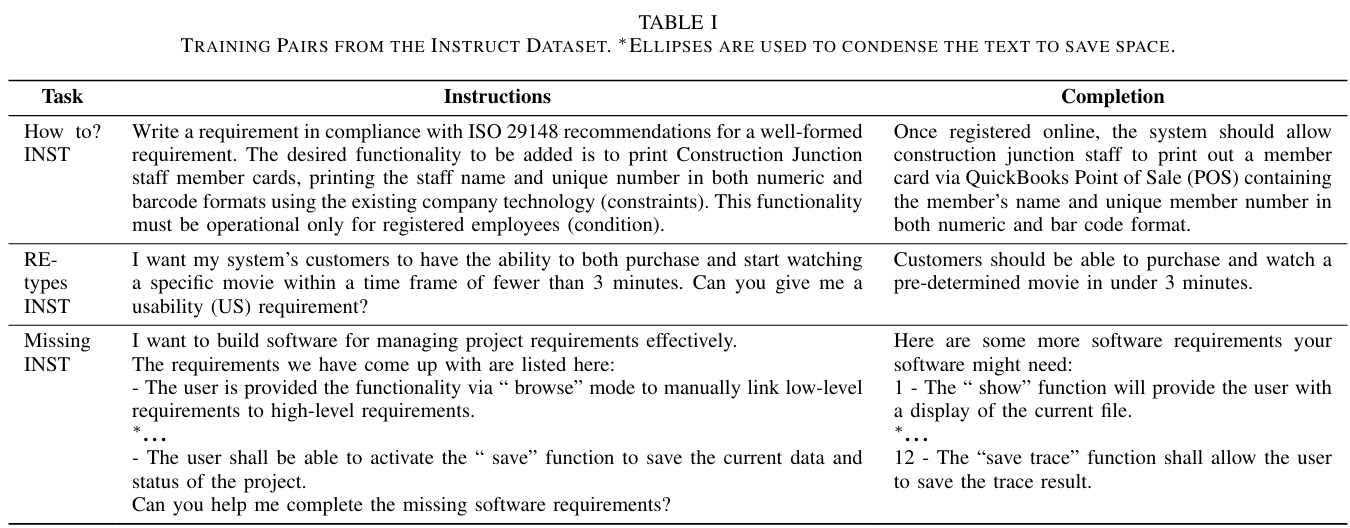
- How-to? INST教模型如何用 ISO 29148 語法撰寫完整需求。例如:指令:寫一條符合 ISO 29148 的需求,功能是讓員工能列印會員卡。完成:系統應允許員工透過 POS 系統列印姓名與會員編號(含條碼)。
- RE-types INST教模型辨識與生成不同類型需求(功能性 vs 非功能性,如可用性、安全性)。例如:指令:給我一條關於「可用性」的需求。完成:顧客應能在 3 分鐘內完成電影購買與播放。
- Missing INST模擬「需求清單不完整」的情境,讓模型補充缺失需求。例如:指令:已有部分需求(瀏覽功能、儲存功能),請補齊其他需求。完成:補充「顯示功能」、「儲存追蹤功能」等缺失項目。
從這份報告的架構,我大致上能理解大語言模型在需求收集這個任務上的基準的表現。現階段大致只能處理通用性需求,但無法深入處理具備特殊商業判斷的需求。
具備商業思維(business know-how)與領域知識(domain know-how),且能從架構設計上思考的軟體工程師或 PM。即便面對 AI 的浪潮,可被取代性還是相對低的。
如果你覺得我內容寫得還不錯,歡迎訂閱我的電子報,我每雙週會發送一封電子報到你的信箱。訂閱連結在這,過往的電子報也在這:Gipi電子報
也鼓勵你可以將我的電子報分享給你認為有需要的朋友們,也許你的舉手之勞,將會改變另一個人的思維與習慣。



