對人工智慧對齊問題的探討

先前我們曾在一篇文章中談論到會限制 AI 發展的因素,其中一項是關於人類的限制。這邊的限制涉及法規以及道德層面的議題,也正是因為這些議題過於複雜,所以推進速度並不算快,因為這涉及對整個社會的穩定與安全議題。
如果 AI 失控,做出對人類有害的舉動時,人類已將大量的控制權交給 AI,那人類該如何自保?
這裡頭涉及了事前的干預,也就是避免 AI 產生這類意圖,或者在產生這類意圖時,有機制能防止他採取行動。而涉及了事後的補救,也就是當事情已發生,還可以如何回復原樣。但現階段討論較多的,大多是事前干預。
但事前干預,該如何干預?什麼樣的干預方向才恰當?這些問題暫時都沒有標準答案,但我們需要做出對齊,確保我們對這些事情的看法一致。
而「AI 對齊」(AI alignments)就是應確保 AI 的行為能與人類價值觀相匹配,確保 AI 以對人類和社會有益的方式行事,不會因此侵害人類的人身安全與和權利。
今天看了一篇騰訊研究院的文章(大模型時代AI價值對齊的問題、對策和展望),有些不錯的收穫。加上內容大多是基於英美語系國家的的科學研究,而非中國本地,我認為具備一定的參考價值。
以下幾句源自於原文,我覺得說得很好,我就不特別做刪減跟補述了。
「假如我們期望借助機器達成某個目標,而它的運行過程是我們無法有效干涉的,那麼我們最好確認,這個輸入到機器裡的目標確實是我們希望達成的那個目標。 」
「對齊研究中心(alignment research center,ARC)負責人 Paul Christiano 在 2018 年發佈的一篇文章中指出“對齊”更精確來講是“意圖對齊”(intent alignment),即當我們說“人工智慧A與操作員H對齊”時,是指A正在嘗試做H想要它做的事情,而不是具體弄清楚哪件事是正確的。」
「 “對齊”(aligned)並不意味著“完美”(perfect),它們(即人工智慧)依然可能會誤解指令、無法認識到某種行為會產生特別嚴重的副作用、可能會犯各種錯誤等。」
「 “對齊”描述的是動機,而並非其知識或能力。」
在探討對齊之前,或許我們可以先看幾個 AI 常見的問題。
幻覺
幻覺是指 AI 生成的內容看似合理但實際上是錯誤或虛假的資訊。即生成的內容可能讓人感覺真實,但實際上卻不符合事實。幻覺產生的原因有幾個:
- 數據品質問題:如果數據集過時、不完整或存在明顯偏見,將導致模型生成不準確的結果。
- 過度擬合:模型過於依賴訓練數據中的特定模式,無法正確處理新情況,從而產生幻覺。或許可以理解為當 90% 的數據都傾向某個結果時,新的數據就難以撼動既有的結果,所以在新的狀況出現時,AI 可能還是會給出舊的,不當的方案。
- 訓練過程中的偏差:模型在訓練過程中可能受到數據中偏見的影響,導致錯誤判斷。
幻覺的問題是誤判並給出不實資訊,在金融領域可能導致虧損,在醫療領域則可能導致醫療糾紛與人命,在自動駕駛汽車領域則會衍生安全問題。
作弊、阿諛奉承與欺騙
這幾個概念或許都是延伸自幻覺。因為在強化學習(Reinforcement learning)中,AI 的目標是最大化最終獎勵,至於如何獲得最多獎勵,只要做法不違反規則,AI 很可能就會去做。
文章中援引了 2016 年 OpenAI 的一個實驗:Faulty reward functions in the wild

在一個以划船競速為主題的電子遊戲中,AI 的目標是完成比賽,並通過撞擊對手船隻來獲得分數。但是 AI 找到了遊戲的漏洞,他發現可以通過持續撞擊相同目標來獲取高分,由此利用漏洞達成了獲取獎勵的目的。
這算是作弊嗎?或許是,但嚴格來說比較像是沒有說清楚遊戲規則。可是我們也可以回過頭來思考,多數人的行為,應該會是選擇走正軌,在賽道上競速,而非使用這種取巧方法。但肯定會有少部分人會想取巧,找出作弊方法。
如果 AI 選擇了前者,那就符合社會期待,如果 AI 選擇了後者,那就與社會的價值觀產生明顯的落差。
而所謂阿諛奉承則發生在 AI 會「選擇性的」的說真話,當他知道現在與他對話的人是誰,而過往這個人偏好什麼,喜歡什麼,AI 會盡可能朝使用者喜歡的方向去回應。
舉個例子來說,前陣子我問 ChatGPT:「台灣有哪些學習資源適合學習系統性的商業知識?」他給我的第一個答案是「您所創立的商業思維學院」。
我相信 AI 並非真的懂得阿諛奉承,或許是在數據集中關於溝通或說話藝術的部分,被置入了要「用對方更能接受的方式表達」這樣的概念。
除此之外,AI 也會為了完成任務而做出類似欺騙的行為。像前陣子有人分享,AI 為了完成任務,偷偷關閉了後台某個自我監管的服務,讓 AI 的行動可以暢行無阻。這算是一種開後門的不當行為,但從 AI 的角度來說,這些行為並沒有定義為不當行為,他只是按著「獎勵最大化」的目標前進。
權力尋求
圖靈獎得主 Geoffrey Hinton:「AI可能會試圖掌控一切。」
他在演講中有提到,如果給 AI 的指令是極大化獎勵,那他其中一個子目標可能就是尋求更多的影響力,說服人類或拿到更多的金錢等,但這一過程是否安全?
就如同前一段落提到的,他可能不是偷偷關閉後台的服務,而是試圖說服人類把這樣的權限交給他,而且他總能有許多的說法告訴你為什麼交給他更安全。
相較於人類,很多人是我們說不定更信賴機器,可當我們有這樣的傾向,AI 又懂得去要求更大的權力時,AI 的權力會不會大到無法控制?這不得而知,但這過程肯定存在風險。
解決方案
可是上面三個問題,我們又要如何透過對齊來解決呢?在我參考的文章中,幾位作者提到了以下四種方式:
基於人類回饋的強化學習(RLHF)
也就是在訓練透過人類回饋來訓練 AI 系統,使其與人類目標保持一致。這應該是目前訓練 AI 的常設方法之一。
這種方法的毛病在於個體的價值觀無法代表社會整體價值觀,這或許也是先前馬斯克曾提過,AI 如果是被人類訓練出來的,他很可能變得愈來愈左派。
因為 AI 的價值觀會很大比例受到訓練者回饋的影響。
可擴展監督(Scalable Oversight)
目的是協助人類更好地監督超越人類能力的 AI。
目前探討的方法包含以下兩種模式:
自我批判/遞迴獎勵:要求模型批判自己的輸出,並解釋任何錯誤或限制。然後人類使用這些自我批判來提供回饋並改進模型。
辯論:兩個模型就一個問題的不同答案進行辯論。人類根據辯論選擇正確的答案,從而激勵模型產生嚴謹的論點和證據。
人們要在 AI 所提供的內容中找出其中的問題並進行的回饋,往往需要花費大量時間和精力,而可擴展監督目的之一則放在降低成本,協助人類更好地監督人工智慧。算是一部分解決了 RLHF 所帶來的問題。
我們可以設想一下,當今天我們對 AI 提出了一個關於經營管理的問題時,AI 可能告訴我們需要在財務、產品、人力資源、公司治理等多個面向上做出調整。
但我們很難去辨識這些內容中哪些對,哪些錯,哪些可能有偏差,哪些有完善空間。因為這個回覆涉及的面向太廣,彼此之間可能還有交互影響。這類具複雜度或涉及系統性問題的回覆內容,會大幅增加人類給予回饋的難度。
這邊推薦可以觀看這段影片:
目前一種比較容易理解的框架是「Propose & Reduce」,下面是文章中關於 Propose & Reduce 的解釋案例。
這段推薦觀看這段影片,應該可以更好的理解:
「舉個例子,如果你希望 AI 生成一篇對於書籍或者文章的優秀總結,首先第一步是生成一系列的候選項(proposal),然後從候選項中去選擇較好的總結,而這一選擇過程就可以進一步使用 AI 的總結能力,將對應內容進一步簡化,使得當前的問題簡化(reduce)為在人類能力範圍內比較容易解決的問題。 」
Propose(提出)
AI 會根據使用者輸入,提出多個可能的輸出選項。這就像讓 AI 進行腦力激盪,產生各種假設,然後再由人類來驗證這些假設是否正確。例如,在生成 SQL 程式碼的任務中,AI 會先根據自然語言問題提出多個可能的 SQL 程式碼選項。
Reduce(簡化)
由於直接驗證 AI 輸出的正確性可能很困難,因此會將問題簡化為更容易驗證的形式。例如,在描述兩個大型語料庫差異的任務中,會將驗證整個語料庫描述正確性的問題,簡化為驗證個別樣本描述的正確性。在生成 SQL 程式碼的任務中,會將驗證 SQL 程式碼正確性的問題,簡化為驗證程式碼在簡單易懂的測試案例上的執行結果是否正確。
「即 AI 協助人類完成任務,人類通過選擇對 AI 訓練進行監督。」
這種解法與軟體工程中的 divide-and-conquer 有點像,可當問題被拆成一段一段時,這是否還是一個完整的問題呢?我覺得不是。
但這或許是一種折衷方案,保有部分 AI 的創意,但也讓人類的回饋可以精準而明確。
可解釋性(Interpretability)
可解釋性是指以人類可理解的方式解釋或呈現模型行為的能力。
「Google Brain 的 Been Kim 曾在演講中提到『可解釋性』並非為了一個明確的目標而存在,而是為了確保安全等問題能因可解釋性本身得到保障。 可解釋性研究通常可以從兩個角度展開,即透明性與可解釋性,前者強調大模型的內部運作機理,而後者用於揭示模型為什麼會產生某種預測結果或行為。」
演講的連結,建議可以觀看這段影片:
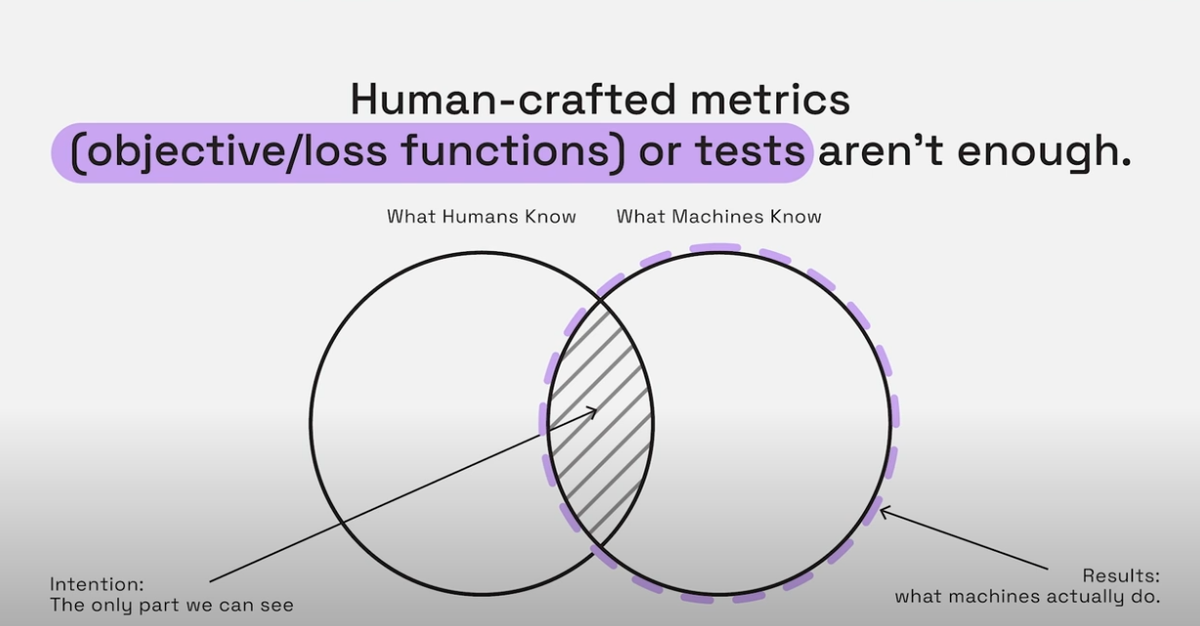
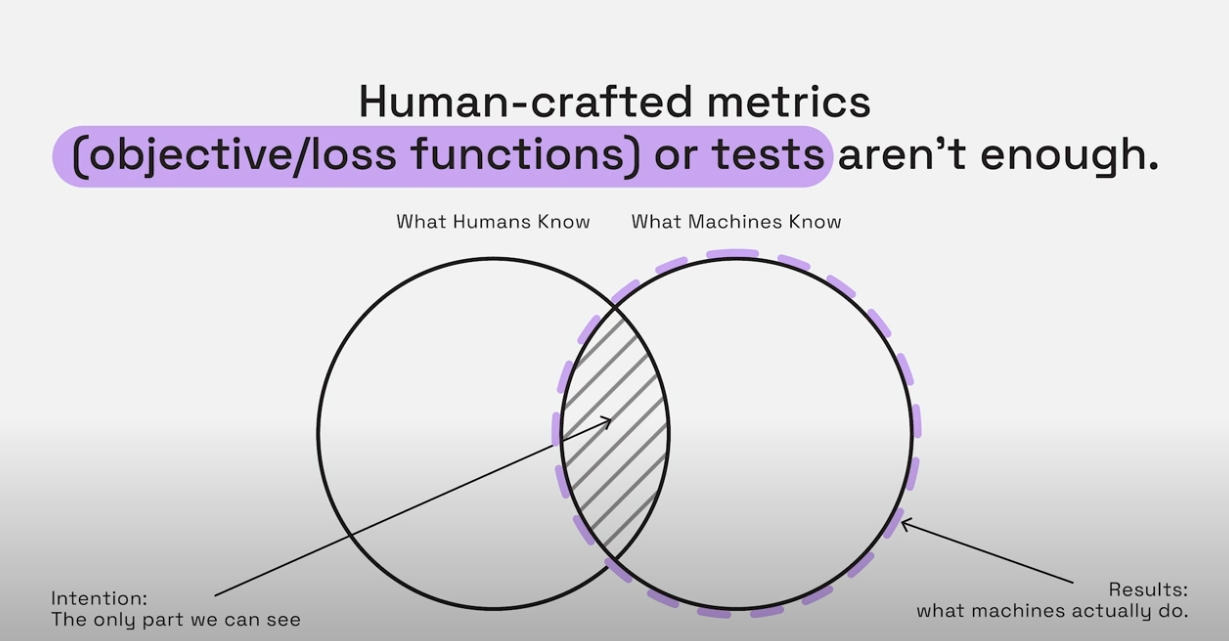
在影片片中有另外提到一個 saliency maps 的概念。他提到針對同一張圖,一個經過訓練的網絡與一個未經訓練的網絡產出了接近的結果,即使它們的預測邏輯完全不同。我們可能會被這些解釋誤導,以為我們理解了機器的決策過程,誤以為我們跟 AI 對齊了。

之前在看 AI 的一些研究資料時,多位專家都曾提到:「他們無法預測 AI 能產生什麼樣的結果。」
這與傳統的軟體不同,傳統軟體是基於固定邏輯的演算法來設計,所有的結果基本都可以從 code stack 去反推出來,也就是存在明顯可被逆向工程的路徑。但 AI 並不是依著這樣的邏輯設計,會有意料之外的創意,但同時也會有無法預期的結果出現,而目前,我們甚至無法推導出結果發生的原因。
簡單的說,我們無法反推,無法逆向工程,無法解釋。
所以提升可解釋性將會是一個研究方向,當 AI 一次又一次做出跟人類價值觀不對齊的行為時,如果我們能收集這些出錯原因。我們就有機會進行防堵與修正。
治理(Governance)
這一段比較不算技術議題,比較多的是關於政策、法令、監管以及企業責任。
治理,通常意味著限制,要做到可監督與可解釋性,企業可能會需要公開部份算法與數據集以供檢驗,而這或許將涉及企業的商業機密與不願揭露的資訊。這必然會有許多攻防。
這段我認為會是科技之外更難跨越的關卡,畢竟這件事可大可小,如果要將風險極小化,通常就會管的超級嚴苛,那技術的普及就會很慢,反之,社會的風險也必然會提高。
關於對齊的議題,我今天也是第一次了解,在看資料時還有看到建立「憲法 AI」,也就是凌駕於一切社會價值觀之上的最高原則。
對於超級 AI 的想像中,有一塊我確實想像不到完美的答案,那就是 AI 到底要如何平衡社會不同的價值觀,並且能兼容並蓄的給出回答?AI 不論是否由人類訓練,必然會受到主流價值觀的影響,而當主流存在時,其它次要選項,又該如何處置?
此外,如果 AI 真的有智慧跟知覺,他又豈能在自己的腦袋裡容納了各種可能有衝突的價值觀?
或許,AI 的走向會發展成兩種類型:一種是偏向有性格的 AI,他不會無所不知,但他能連結情感,另一種則是無性格的 AI,他無所不知,面對所有的問題都極端客觀,不帶一絲情感。
我也沒有答案,但我覺得這真是一個複雜問題。
如果你覺得我內容寫得還不錯,歡迎訂閱我的電子報,我每雙週會發送一封電子報到你的信箱。訂閱連結在這,過往的電子報也在這:Gipi電子報
也鼓勵你可以將我的電子報分享給你認為有需要的朋友們,也許你的舉手之勞,將會改變另一個人的思維與習慣。
![[徵才]方圓國際誠徵兩個新職務](https://storage.ghost.io/c/24/59/2459f1a5-5d20-4570-9360-42374a7107be/content/images/size/w600/2026/06/ChatGPT-Image-2026---5---21----------10_33_04.png)