
對 DeepSeek 我的一些想法


過年期間 DeepSeek 的新聞幾乎霸佔了多數媒體的版面,直到現在,我個人的 Facebook 與常看的一些媒體、部落格也還經常看到 DeepSeek 的相關討論。
由於前段時間我人在韓國旅行,沒有太多的時間深入細節看 DeepSeek 的資料,尤其是有部分內容涉及到較深入的技術細節,沒看懂的狀況下實在也不好亂說。
回台灣這幾天終於有點時間可以好好看一下資料,以下我大概整理了一些觀點供大家參考。
DeepSeek 的技術創新
DeepSeek 揭露的資訊中提到 DeepSeek-V3 的訓練成本大約是 OpenAI 的 1/10 不到。主因是 DeepSeek 在技術架構中實現了以下創新。
- 混合專家(Mixture-of-Experts, MoE)架構:DeepSeek-V3 擁有 6,710 億參數,但在實際運行中,每個輸入僅激活 370 億參數,這種選擇性激活的方式大大降低了計算成本,同時保持了高效能。
- 無輔助損失的負載平衡策略(auxiliary-loss-free load balancing strategy):這不是新東西,但核心概念是最小化因負載平衡對模型運行效能的負面影響。簡單的說,傳統的負載平衡有多餘的浪費,這套方法則可大大減少浪費。
- 多頭潛在注意力(Multi-Head Latent Attention, MLA):MLA 通過低秩聯合壓縮技術(Low-Rank Key-Value Joint Compression),減少了推理時的鍵值(Key-Value, KV)快取,能在維持效能的同時顯著降低了記憶體佔用,進而實現更高效的訓練和推理。
- 多 token 預測模型(Multi-Token Prediction Model):傳統的 token 處理是循序式的,也就是第 N+1 個 token 是根據第 N 個 token 來處理,而多 token 模式則是同時對多個 token 展開處理,此策略提升了模型的整體效能表現。但我個人的疑慮是會占用更多的運算資源。
- 高效率的訓練架構:採用HAI-LLM 框架,支援16-way Pipeline Parallelism(PP)、64-way Expert Parallelism(EP)和ZeRO -1 Data Parallelism(DP),並透過多種最佳化手段降低了訓練成本。
上面這些是 DeepSeek 在 V3 版本所提出的關鍵創新,其中MoE 架構、無輔助損失的負載平衡策略算是早就存在的技術,不過 DeepSeek 將其運用在技術架構中,顯著提升了效能。而多 token 預測模型其實是 Meta 先提出並開源的解決方案。
多頭潛在注意力則是在 NLP 的 transform 模型中早就有人使用技術,或許也稱不上是由 DeepSeek 首創。但值得注意的是 DeepSeek 有能力在將這項技術加以改良並應用在現行產品上。
看到這,或許你會覺得我想告訴大家 DeepSeek 並沒有什麼了不起的創新,因為他們只是用了別人的技術。
但我的觀點正好相反,每次看到這類將既有技術整合後實現創新的案例,總會讓我想到賈伯斯說過的一段話:「好的藝術家懂複製,偉大的藝術家則擅偷取。」
也有人彙整了賈伯斯的概念提出「創新即借用與連結」這樣的觀點。
當 iPhone 被推出時,市場上雖然震驚,但也有很多人說其實 iPhone 並沒有什麼原創技術,大多的技術都已存在一段時間,賈伯斯只是發揮創意,將這些技術整合,進而實現應用創新。
這就是所謂的借用與連結。
現在,不會有人說賈伯斯沒什麼了不起,因為他確實顛覆了人們看待電話與電腦的習慣,引領了整個行動網路年代。
創新的要件
在 2023 年我曾在工研院分享過 OpenAI 的成功軌跡。當時我提到「OpenAI 的成功,很大一部分跟時機有關。」
為什麼我這麼說呢?
在實現 GPT-4 這項劃時代的創新時,如果不是晶片技術與雲端運算服務的成熟,空有演算法並無法解決運算速度的問題。所以這些技術是支撐 GPT-4 的技術基礎建設。
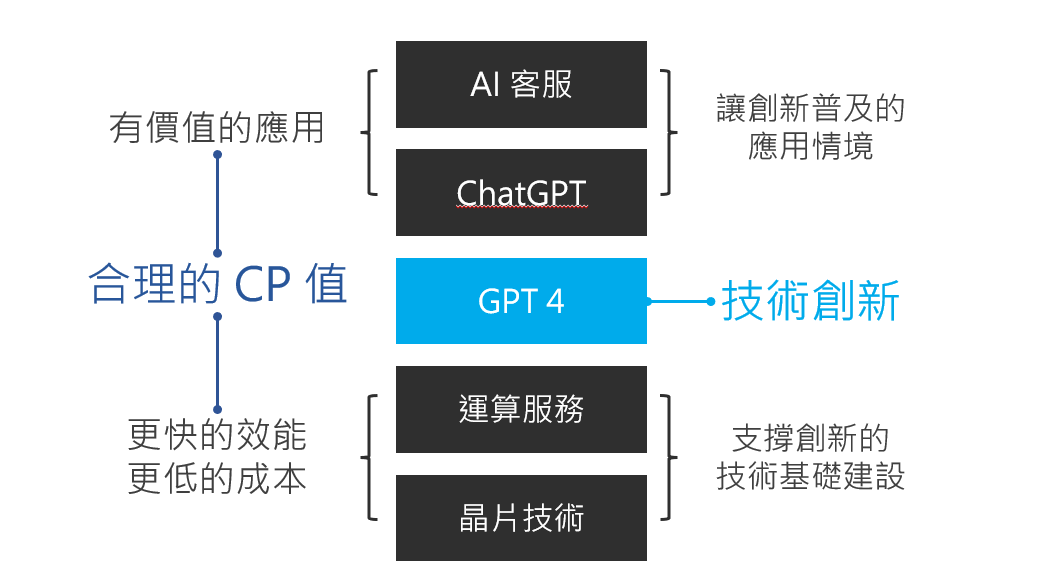
但真正讓 OpenAI 為世人所看見,並能在短短的兩年多的時間風靡全球,成為當前最熱門的科技議題,ChatGPT 功不可沒。先進的技術,如果不能普及到世人的生活中,發展的速度通常非常慢。
ChatGPT 建構了一個所有使用者都可以輕易互動的介面,而且能回答的問題也不局限於特定專業領域,讓所有使用者都能輕易上手。這種能讓創新迅速普及的應用情境非常關鍵。
如果沒有 ChatGPT,OpenAI 現在可能只是間技術很先進的公司,但因為 ChatGPT 這個有趣的應用,當年便成為有史以來使用者人數成長最快的應用。
而往後的每間 AI 公司其實也努力的複製這種模式,因為搶占市場最快的方法是提供一個簡單易入手的應用,並讓大家在使用這個應用的過程產生快感(AHA monent)。
這個段落我簡單總結一下,這個年代的創新很難是橫空出世,絕大多數都要奠定在既有的技術基礎建設,並在這個基礎上做出一定程度的創新,並建構一個能讓創新普及的應用。
OpenAI 如此,DeepSeek 也是如此。
而在上面這張圖中,我同時也提到了更快的效能與更低的成本。這其實是所有企業不變的追求。OpenAI / DeepSeek 都在這兩塊上努力,只是 OpenAI 可能更偏重效能,而 DeepSeek 則是更看重後者。
DeepSeek 的真正價值,讓更多 AI 應用創新發生
OpenAI 引領了 AI 的浪潮,研發方向朝向更大規模的算力,更大量的數據,更複雜的模型,投入更多的資源。而 DeepSeek 則試著更小,更輕薄,更低成本。兩者的思考路線不同,但在解決的核心問題其實都是讓 AI 更普及,更為世人所用。
OpenAI 的模式,自然會需要持續墊高硬體資源,而這也是 NVIDIA 的重要性會愈來愈高的原因之一。而 DeepSeek 則反其道而行,即便擺脫不了對硬體的依賴,但已經大幅降低對硬體的需求。
這兩種不同切入路線,也讓我想到距今近 20 年的科技發展。早年企業為了獲取更多的運算資源時,會傾向建置大型主機,但大型主機建置與維護的成本超級高,根本不是一般企業能負擔得起。所以在那個年代,運算資源的取得超級昂貴,許多的應用創新也因此受限。
研發與生產大型主機的企業,在那個時代壟斷了算力。但方法是人想出來的,後來開始有人提出分佈式運算的架構,讓相對低階的硬體,可以透過分工的方式來完成複雜運算,並結合虛擬化技術讓運算資源的分配可以某種程度由軟體決定,而這也是雲端運算底層的架構之一。
看到這,我想大家應該也能想像到,OpenAI 做的事比較像傳統大型主機企業在做的事,而 DeepSeek 則是朝向早期分佈式運算架構解決方案的廠商在做的事。
分佈式運算架構進一步催生了雲端運算(cloud computing)年代,讓運算資源的取得變得容易且便宜,進而讓更多的 SaaS(Software as a Service)應用蓬勃發展。
DeepSeek 則是讓 AI 資源的取得變得更容易且便宜,肯定也能促進 AI 應用的蓬勃發展。
我們可以想像,當建置與取得成本變成 1/10 時,將會有多少原先裹足不前的企業開始投入。我們甚至可以預見,有價值的創新將會以百倍的速度發展開來。
而我相信,這將會是 DeepSeek 帶來的最大價值。
DeepSeek 的爭議不重要嗎?
在談論 DeepSeek 的議題時,有些人會著重於談論技術嫖竊與安全性問題。也就是透過蒸餾 OpenAI 的數據來獲取自己的數據,以及數據會回傳中國的議題。也有人提到 DeepSeek 可能造假,或者運用對自己有利的方式來美化測試數據。又或者提到 DeepSeek 的成本其實只有模型建置成本,但沒有將整體研發成本計算進去等等。
這些議題,對個人來說重要性其實沒那麼高,因為你可以選擇不使用它的服務。就像政府機構禁用 DeepSeek,你也可以選擇不用 DeepSeek 的公開服務。
但既然 DeepSeek 已經開源了,那你大可站在他們的肩膀上做研究,而不要重頭開始造輪子。深入了解一下他們在 MoE、MLA 跟負載均衡上的創新,也學習一下它們如何將這些現行技術加以整合後創造新應用。
我們可以有自己的觀點去評論這些有爭議的部分,但我更建議可以從學習的角度思考。看看 DeepSeek 有哪些技術思路是我們可以借鑑,增廣自己創新的眼界,站在別人肩上思考。
從事研發與產品開發工作這麼多年來,多數時刻我都在做技術應用與整合上的創新,真正純技術創新(業界首創或專利型)比例其實沒那麼高,或許只占整體比例的 20% 不到。
台灣乃至全球的多數企業,真正競爭的場合,其實也是在應用而非底層技術上。純技術的競爭,大多是由技術大廠所驅動,而我們多數人,一定要把握的則是技術應用上的創新。
如果你覺得我內容寫得還不錯,歡迎訂閱我的電子報,我每雙週會發送一封電子報到你的信箱。訂閱連結在這,過往的電子報也在這:Gipi電子報
也鼓勵你可以將我的電子報分享給你認為有需要的朋友們,也許你的舉手之勞,將會改變另一個人的思維與習慣。

![[徵才]方圓國際誠徵兩個新職務](https://storage.ghost.io/c/24/59/2459f1a5-5d20-4570-9360-42374a7107be/content/images/size/w600/2026/06/ChatGPT-Image-2026---5---21----------10_33_04.png)